SICP 1.1 - The Elements of Programming - Part 2
Covering the SICP material from sections 1.1.7 through 1.1.8 and Exercises 1.4 through 1.8
Table of Contents
Part 2 of my work on Chapter 1.1 of Simply Scheme, including notes and exercises.
See Part 1 here https://blog.justinmallone.com/sicp-11-the-elements-of-programming-part-1/
See the SICP chapter here http://sarabander.github.io/sicp/html/1_002e1.xhtml
Note that a Ulysses bug is making it problematic to paste code markdown into blockquotes. In some of my blockquotes from SICP there is code formatting in the original that is not quoted here. The Ulysses people are aware of the bug but no ETA on when they'll fix it 😔
Note that I'm reconsidering how I should go about formatting these posts. See this post for more info or to comment https://discuss.criticalfallibilism.com/t/justin-does-sicp/96/5?u=justinceo
I've added Disqus comments. While i intend to use the forum I just linked as my primary place for discussing these posts, I wanted to enable people to comment on my blog and offer criticisms or point out errors without having to sign up for a paid forum.
Notes
1.1.7 - Example: Square Roots by Newton’s Method
This section describes computing square roots by Newton's method using successive approximations.
Suppose you want to compute the square root of 2. The method is to take an initial guess (let's follow the book and suppose the initial guess is 1) and take the quotient of the number whose root you are trying to find and your guess (in our example, 2 / 1, or 2.) Then you take that quotient, add it to your guess, and get the average of the quotient and your guess. Then you take that average value, and that becomes your new guess, and you repeat the process.
The SICP authors indicate they're going to attempt to put this into code. I made my own attempt at doing so before reading theirs.
(define (sqrt-iter guess x)
(let ((newguess (/ (+ (/ x guess) guess) 2)))
(if (< (abs (- guess newguess)) .001) newguess
(sqrt-iter newguess x))))
I know they didn't introduce let yet but I wanted to use it. 🙂 I use newguess three times in the body, so it seemed reasonable to give it a name...
Hopefully this is pretty readable, but the basic logic here is as follows: if the absolute value of the difference between the guess that we already had and the newguess that we just calculated is less than .001, return the newguess. Otherwise, recursively invoke sqrt-iter with the newguess.
Checking for absolute value of the difference between the guesses ensures that our function works correctly even when our old guess is lower than our new guess.
The point at which the difference between the guesses is less than .001 is just the cutoff point I somewhat arbitrarily decided as being "good enough".
The procedure seems to work, though with the caveat that the output is in my DrRacket fractions, which looks a bit weird.

So let's see what they say and compare it to my naive attempt.
Ok first they lay things out in pseudocode:
(define (improve guess x)
(average guess (/ x guess)))
(define (average x y)
(/ (+ x y) 2))
(define (good-enough? guess x)
(< (abs (- (square guess) x)) 0.001))
(define (sqrt-iter guess x)
(if (good-enough? guess x)
guess
(sqrt-iter (improve guess x) x)))
(define (sqrt x)
(sqrt-iter 1.0 x))
Note that the square of the guess is being compared to the number whose root you are trying to determine in good-enough?. Whereas in my procedure, I was comparing the current guess to what would be the next guess.
The organization is much more compartmentalized into subprocedures. Also, in my solution I kind of forgot about the context that we're trying to make a square root procedure. In that context, it makes sense that we'd want to have the overall procedure be sqrt and not sqrt-iter, which is a procedure about a specific method for solving the sqrt problem.
1.1.8 - Procedures as Black-Box Abstractions
This section discusses how sqrt-iter is recursive, and discusses the approach of decomposing a problem into smaller parts that make sense (as we did with good-enough?, improve and so on.)
It also has a section on local names and bound variables versus free variables. It discusses how the meaning of formal parameters is local to the body of a procedure. E.g. if you have
(define (square x) (* x x))
and then
(define (good-enough? guess x)
(< (abs (- (square guess) x)) 0.001))
The x in good enough is a different x than the square. The relationship between a particular value and the x that exists for x as a formal parameter only exists within the body of the procedure where you're using the x. (My side comment: this is similar to let expressions, except those can be even more local than a procedure - they might only associate a name with a value for part of a procedure).
This section also discusses the idea of making subprocedure definitions local to a particular procedure, because you might e.g. have a bunch of different procedures you'd want to name good-enough? in a big library, and it's a better system of organization to keep these subprocedures localized to the particular procedure than to have a big pile of separate different subprocedures.
It presents the following as version 1 of applying this localization-of-procedures idea to sqrt:

The book then builds on the idea of local names/bound variables. It mentions
that:
Since x is bound in the definition of sqrt, the procedures good-enough?, improve, and sqrt-iter, which are defined internally to sqrt, are in the scope of x.
With the old structure, where everything was in separate procedures, we had to do explicit handoffs of values between procedures so that e.g. good-enough? would have access to the number whose value we were trying to find the square root of (as represented by the x formal parameter in sqrt). But since we've put everything in the body of the same overall procedure, we don't need those explicit handoffs anymore.

Exercises
Exercise 1.4 ✅
Observe that our model of evaluation allows for combinations whose operators are compound expressions. Use this observation to describe the behavior of the following procedure:
(define (a-plus-abs-b a b)
((if (> b 0) + -) a b))
I found their "observation" a little difficult to follow. I wrote the following to try to understand it better:
- my guess is that the "model of evaluation" they're referring to is applicative order. I'm not quite following their point, however. Are they saying that the above wouldn't work in in normal order? E.g. that you can't have combinations whose operators are compound expressions?
(Edit: I still don't quite follow this even after figuring out Exercise 1.5) - a combination is an expression "formed by delimiting a list of expressions within parentheses in order to denote procedure application", such as
(+ 2 7). - similarly, a compound expression is formed by, for example, combining a procedure like
+with some numbers. - an operator is the left-most element in a list - it's the thing that's you apply to the operands (like numbers) in a combination/compound expression.
So I think the bottom line here is "given how we evaluate things, we can have a big thing like (if (> b 0) + -) as an operator. Given that, evaluate the procedure."
So basically, if b is greater than 0, the + gets applied as an operator to a and b. otherwise, the - gets applied as an operator to a and b. The result is that the absolute value of b always gets added to a.
So basically, if we change the value of b from positive to negative but leave a the same, it won't make a difference to the result, but it will make a difference if we change a's sign. That's just what we see:

Exercise 1.5 ✅
Ben Bitdiddle has invented a test to determine whether the interpreter he is faced with is using applicative-order evaluation or normal-order evaluation. He defines the following two procedures:
(define (p) (p))
(define (test x y)
(if (= x 0)
0
y))
Then he evaluates the expression
(test 0 (p))
What behavior will Ben observe with an interpreter that uses applicative-order evaluation? What behavior will he observe with an interpreter that uses normal-order evaluation? Explain your answer. (Assume that the evaluation rule for the special form
ifis the same whether the interpreter is using normal or applicative order: The predicate expression is evaluated first, and the result determines whether to evaluate the consequent or the alternative expression.)
Short Answer
Summing up the expected behavior for test:
- in an applicative order language,
testwill infinitely loop due top, which loops infinitely, getting evaluated whentestis initially invoked. - in a normal order language,
testwill return 0, due to only the x ever getting evaluated because of how normal order works and how theifis constructed.
Long Explanation
So first up, it's worth noting that p is a procedure that calls itself , and then calls itself again, and so on, forever. So once it gets called, it's in an infinite loop.
Given what the book says about the special form if having the same evaluation rule, I was initially a bit confused. It seemed like perhaps it shouldn't make a difference whether applicative order or normal order is being used, given the use of the same evaluation rule for if. It seemed like in either case, p should never get evaluated.
But it was clear from my testing in DrRacket that p is getting evaluated in Scheme, which is an applicative order language, because it goes into an infinite loop.
So I had to revise my theory. I now think that the issue is that the values get evaluated in the test procedure when you initially invoke it (in the applicative order model). This follows from the book's description of the model. The if is a bit of a red herring - it's not central to thinking about the fundamental difference in how the procedures operate vis-a-vis the applicative vs normal order issue (although you do need to consider the if to determine what exactly will get returned in a normal order evaluation).
So to bring things out of the clouds, when you type (test 0 (p)) in an applicative order language, the stuff you type gets evaluated and then applied. So the interpreter basically proceeds as follows:
- "Ok, what's the value of
test? ok it's a procedure with an if statement, great." - "What's the value of 0? okay that's just a number, 0, great."
- "what's the value of
p? ok it'sp. and what's the value ofp? ok it'sp. and what's the value of..." and so on. But ifpwas something non-infinite-loop-causing, like say the number 2, then it would say "ok greatpis 2. let's do this thing and evaluate!"
Whereas with normal order, when you type (test 0 (p)), the interpreter goes
- "okay, but what's test?"
- "okay, it's a procedure with an
ifstatement, great. Let's take these arguments we haven't evaluated and bring them into thisifstatement. Don't worry, we'll get around to evaluating them when we need to!" - "okay, so what's the predicate of this
if? okay we're seeing if x is equal to 0." - "okay we're gonna have to see what x is now to do this thing. what's x? okay it's 0."
- "okay so the predicate is
= 0 0. that's true!" - "so what should we return? 0! okay we're done."
and then if the interpreter was a curious sort, it might reflect afterwards "Hmm I wonder what p was?? 🤔 I never got to find out!"
Regarding applicative order, I noticed a line in my previous post about this topic whose meaning wasn't fully clear to me at the time I wrote it.
Applicative order first evaluates the operator and operands and then applies the resulting procedure to the resulting arguments.
I think I was parroting the book a bit here, without fully grasping the meaning. But I think I'm clearer on the meaning now after considering this Exercise at length and in detail.
Exercise 1.6 ✅
Alyssa P. Hacker doesn’t see why if needs to be provided as a special form. “Why can’t I just define it as an ordinary procedure in terms of cond?” she asks. Alyssa’s friend Eva Lu Ator claims this can indeed be done, and she defines a new version of if:
(define (new-if predicate
then-clause
else-clause)
(cond (predicate then-clause)
(else else-clause)))
Eva demonstrates the program for Alyssa:
(new-if (= 2 3) 0 5)
5
(new-if (= 1 1) 0 5)
0
Delighted, Alyssa uses new-if to rewrite the square-root program:
(define (sqrt-iter guess x)
(new-if (good-enough? guess x)
guess
(sqrt-iter (improve guess x) x)))
What happens when Alyssa attempts to use this to compute square roots? Explain.
Short Answer
An infinite loop occurs due to applicative order evaluation and the recursive call in sqrt-iter.
Explanation
The "real" if is kind of like a railroad switch that throws the evaluation of the procedure onto one track or the other depending on the truth value of the predicate statement. That's not the general rule though - the general rule is applicative order. new-if using a cond clause can definitely control what value is returned - we see that with the working examples that Eva demonstrates. But the use of cond to build new-if doesn't override the applicative order default evaluation order within the body of new-if. This means that despite Eva's best intentions, within the body of sqrt-iter, the values of the operators and operands will be evaluated. Because there is a recursive call in sqrt-iter, this leads to an infinite loop.
Exercise 1.7 ❌
Exercise 1.7: The good-enough? test used in computing square roots will not be very effective for finding the square roots of very small numbers. Also, in real computers, arithmetic operations are almost always performed with limited precision. This makes our test inadequate for very large numbers. Explain these statements, with examples showing how the test fails for small and large numbers.
Here's the original, flawed version of the procedure I tested:
(define (square x)
(* x x))
(define (sqrt-iter guess x)
(if (good-enough? guess x)
guess
(sqrt-iter (improve guess x) x)))
(define (improve guess x)
(average guess (/ x guess)))
(define (average x y)
(/ (+ x y) 2))
(define (good-enough? guess x)
(< (abs (- (square guess) x)) 0.001))
(define (sqrt x)
(sqrt-iter 1.0 x))
Problem With Very Large Numbers
For a very large number, the limited precision of the arithmetic operations coupled with the square guess approach in good-enough? result in the procedure never getting the guess anywhere near our threshold for being "good enough." See (sqrt 500000000000000000000000) and run a trace on the procedure and its subprocedures for an example.
Here's some output from after the point at which the procedure has already reached the point at which it's not going to get any closer with its guesses.
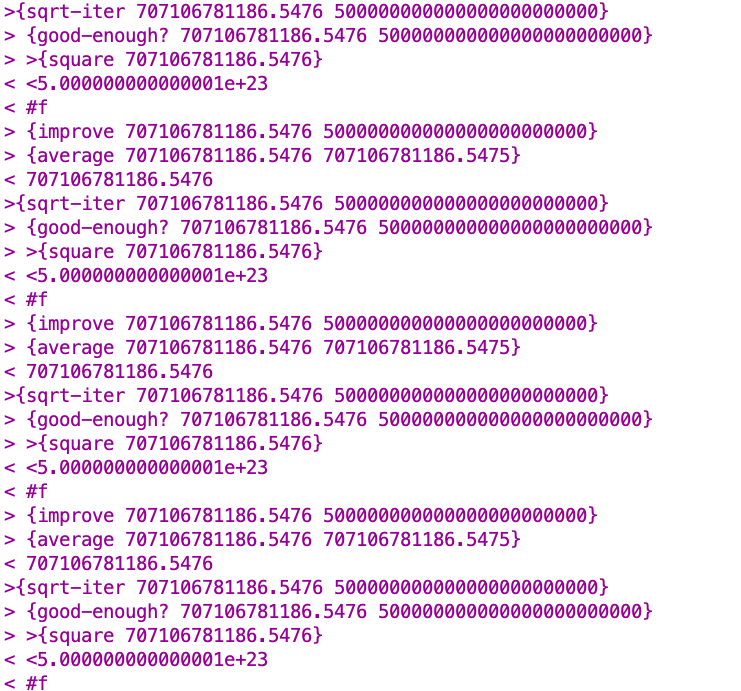
The limited number of digits that DrRacket is keeping track of prevents our guess 707106781186.5476 from being improved upon to the point where it could actually get within our "good enough" threshold.
(Note that I added after writing my initial answer: this is explained in detail in Sébastien Gignoux's answer to this problem. One thing interesting noted there, that I didn't catch at first in my own answer, is that sometimes, even with the flawed procedure, you get lucky. E.g. suppose you try to find the square root of 12345678901230. The flawed procedure eventually tries to guess 3513641.828819494 as the square root. When my version of Scheme squares that, it gets 12345678901230.0, which is of course within 0.001 of 12345678901230 since it's just a representation of the same number...this is obviously not something you can count on, however).
Problem With Very Small Numbers
For very small numbers, the issue is that the threshold for being a good enough guess gets crossed too early. Suppose we want to find (sqrt 0.000001). The actual square root of 0.000001 is 0.001. In the course of trying to find a solution, our procedure guesses a number like 0.031260655525445276 as the square root (details may vary depending on your implementation of Scheme). The square of that guess is 0.00097722858. Given that the first non-zero digit there is in the ten-thousandths place and the value we're looking for the square root of (0.000001) has its first non-zero digit in the millionths place, that seems like a weird place to stop looking for square roots. But because the difference between 0.00097722858 and 0.000001 is less than 0.001, we do stop there (erroneously) and get a very mistaken value from our square root procedure.
An Alternative Strategy
An alternative strategy for implementing good-enough? is to watch how guess changes from one iteration to the next and to stop when the change is a very small fraction of the guess. Design a square-root procedure that uses this kind of end test. Does this work better for small and large numbers?
BTW I went through a bit of SICP before, so that's probably why i defaulted to the basic method of solving the problem that they suggest in this exercise when writing my stuff up above in the Notes section.
First Solution Based on Misreading
I actually badly misread/misunderstood the prompt initially. I misread the part that talked about how "to stop when the change is a very small fraction of the guess." (emphasis added). Instead I implemented a solution that decided that a guess was good enough when the new guess was within a very close range of the old guess. What's interesting is that it seemed to work okay, and better than the original procedure. Here was my mistaken solution:
(define (good-enough? guess x)
(< (abs (- (improve guess x) guess)) 0.00001))
And I otherwise reused their code from the chapter:
(define (improve guess x)
(average guess (/ x guess)))
(define (average x y)
(/ (+ x y) 2))
(define (sqrt-iter guess x)
(if (good-enough? guess x)
guess
(sqrt-iter (improve guess x) x)))
(define (sqrt x)
(sqrt-iter 1.0 x))
Difference Between My Solution and The Intended Solution
So since I made a mistake let's analyze it. What's the difference in how my solution works versus how the solution the authors had in mind works?
Here's the original, flawed good-enough?
(define (good-enough? guess x)
(< (abs (- (square guess) x)) 0.001))
Here's my mistaken solution:
(define (good-enough? guess x)
(< (abs (- (improve guess x) guess)) 0.00001))
And here's an example of a correct solution that would work in the context of the original procedure:
(define (good-enough? guess x)
(< (abs (/ (- (improve guess x) guess) guess)) 0.00001))
The key difference between my flawed solution and the correct solution is that my solution isn't looking at whether the change in the guess is a small fraction of the guess. Instead, it's just looking at whether the size of the change in absolute terms is less than some value. My flawed solution is saying "Is the absolute value of the difference between an improved guess and a current guess less than 0.00001?" What we wanted is more like "Ok, figure out the difference between the current guess and a new-and-improved guess. Divide that difference by the current guess. Is the absolute value of that less than 0.00001?"
Why do we want to ask that latter question, and not what I asked? My solution seemed to be an improvement over the original, after all. But I think that with the correct solution, the 0.00001 represents a fraction of the guess. So it's the procedure is keyed in some way to the size of the guess. Whereas in my solution, it's looking at whether there's been an absolute change in the size of the guess. My intuition is that while my solution might perform better than the original in some situations, it's still going to have problems with very small numbers compared to the correct solution, because it's using an absolute threshold and not something keyed to the size of the guess. Let's test this out with (sqrt 0.0000000000000000000000000000001)
The correct answer (per google) is 3.1622777e-16
My flawed solution gives 1.52587890625e-5 in Scheme.
The correct solution gives.... 3.1622776609717765e-16 in Scheme. Not bad
Exercise 1.8 ✅
Newton’s method for cube roots is based on the fact that if y is an approximation to the cube root of x, then a better approximation is given by the value
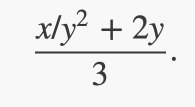
Use this formula to implement a cube-root procedure analogous to the square-root procedure. (In 1.3.4 we will see how to implement Newton’s method in general as an abstraction of these square-root and cube-root procedures.)
Using the improved/corrected version of the square root procedure (in light of Exercise 1.7) as my point of departure, I made a cube root procedure. The substantive changes were primarily only in the improve subprocedure, in which I implemented the formula described in the exercise prompt. I also changed what gets passed to good-enough? in order to make it more readable, as I was finding it a little confusing and thought the readability could be improved.
I also special-cased 0 since that was coming out weird otherwise:

(Note added after writing my initial answer: aelanteno noticed another special case: -2. I haven't delved into the details of her solution, but the upshot seems to be that you want to set the initial guess to 2 instead of 1. I tried out just making that change in general, instead of only when x = -2 like aelanteno did. That seemed to work, so I made that small change to my procedure).
(define (square x)
(* x x))
(define (improve guess x)
(/
(+
(/ x
(square guess))
(* 2 guess))
3)
)
(define (good-enough? guess newguess)
(< (abs (/ (- newguess guess) guess)) 0.00001))
(define (cbrt-iter guess x)
(if (good-enough? guess (improve guess x))
guess
(cbrt-iter (improve guess x) x)))
(define (cbrt x)
(if (= x 0) 0
(cbrt-iter 2.0 x)))
Unanswered Questions
- What exactly did the authors have in mind by the statement "Observe that our model of evaluation allows for combinations whose operators are compound expressions." in Exercise 1.4?