SICP 1.1 - The Elements of Programming - Part 1
Covering the SICP material from sections 1.1.1 through 1.1.6 and Exercises 1.1 through 1.3
Table of Contents
Notes
My work on Chapter 1.1 of Simply Scheme, including notes and exercises. See the chapter here http://sarabander.github.io/sicp/html/1_002e1.xhtml
This version of SICP is notably more nicely formatted than others, and has nice features like the footnotes popping up over the current text when you click on them.
My own notes will be short summaries/general descriptions, plus longer tangents on anything I'm confused about, didn't quite follow, or found interesting. They definitely aren't a substitute for the book, especially in these early chapters where a lot of the material is going to be Simply Scheme review for me that I'll likely be powering through pretty quickly.
I try to do the exercises without help and then I reflect my own judgment of how I did with the use of emoji such as ✅ and ❌. Criticism on self-evaluations is welcome, as is criticism regarding code elegance, reasoning errors, misstatements, and so on.
Initial DrRacket Setup
I had to do some setup in Dr Racket on my Mac.
I found a Stack Overflow answer and was able to follow the steps in the heading "1. From the Package Manager". I also had to go to Language/Choose Language/Show Details/ and change the value in "Always use the same #lang line" to #lang sicp instead of the Simply Scheme stuff that was there Before. For some reason - maybe some Dark Mode bug? haven't tested - the text in that field was invisible unless I highlighted it. Weird.
I also added the following line so I could run trace:
(#%require racket/trace)
1.1.1 - Expressions
This section discusses expressions, and describes even a number as an example of an expression. The section also describes a combination as an expression formed by delimiting a list of expressions in order to denote procedure application. So, for example, (+ 137 349) is a combination.
This section covers some stuff I'm already familiar with, such as what prefix notation is, the meaning of operator and operands, and so on.
1.1.2 - Naming and the Environment
This section goes over associating names with values and talks about using define. It also mentions the existence of a global environment as a memory that keeps track of name-object pairs.
1.1.3 - Evaluating Combinations
This section presents the following procedure for evaluating combinations:
1. Evaluate the subexpressions of the combination.2. Apply the procedure that is the value of the leftmost subexpression (the operator) to the arguments that are the values of the other subexpressions (the operands).
SICP points out that this evaluation procedure is recursive in nature (on account of step 1). It then applies this procedure to a specific example:
(* (+ 2 (* 4 6)) (+ 3 5 7))
This example gives us the opportunity to consider our first tree:
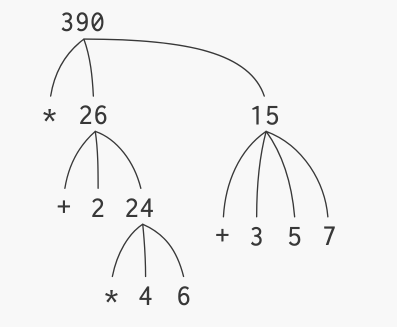
The values of the sub-expressions "percolate" upwards as the sub-expressions are evaluated (e.g. (+ 3 5 7)) are evaluated.
SICP notes that define is an example of an exception to the above procedure - a special form - since it does not apply define to two arguments (x and 3, respectively)
SICP hasn't actually defined sub-expressions or expressions in a rigorous way, so above I gave a sort of intuitive interpretation when I treated (+ 3 5 7) as a sub-expression of the larger expression. However, a sub-expression could be any component of an expression, including a number or operator like +. SICP addresses this issue as follows:
Next, observe that the repeated application of the first step brings us to the point where we need to evaluate, not combinations, but primitive expressions such as numerals, built-in operators, or other names. We take care of the primitive cases by stipulating that
– the values of numerals are the numbers that they name,– the values of built-in operators are the machine instruction sequences that carry out the corresponding operations, and– the values of other names are the objects associated with those names in the environment.
1.1.4 - Compound Procedures
This section discusses procedure definitions, and the power of abstraction they allow. SICP describes the form of a procedure definition as follows (and I'm already familiar so I won't go into detail):

There's a syntax note in footnote 13 that:
Throughout this book, we will describe the general syntax of expressions by using italic symbols delimited by angle brackets-e.g., ⟨name⟩-to denote the "slots" in the expression to be filled in when such an expression is actually used.Throughout this book, we will describe the general syntax of expressions by using italic symbols delimited by angle brackets-e.g., ⟨``name``⟩-to denote the "slots" in the expression to be filled in when such an expression is actually used.
I just realized that these "long" angle brackets (as opposed to < and >) are pretty non-standard - you don't see them used often.
1.1.5 - The Substitution Model for Procedure Application
This section discusses the substitution model. It gives the following description of how to apply compound procedures (as opposed to primitive procedures) to arguments:
To apply a compound procedure to arguments, evaluate the body of the procedure with each formal parameter replaced by the corresponding argument.
It gives an extended example on this point using a function that passes an argument to a sum-of-squares function along with some pre-determined values.
(define (f a)
(sum-of-squares (+ a 1) (* a 2)))
A 5 is passed in as the argument a and is shown being substituted into the function in place of the a.
SICP explains that the model of substituting in values is a mental/conceptual model that we use in order to help us understand the function. It's not actually what is going on inside the interpreter. What actually happens is described later in the book. Also, SICP says that we're going to proceed through different models as we progress in order to deal with the details we learn about. One thing that the substitution model can't handle is mutable data.
A meaty concept introduced in this section - and one I've had a bit of difficulty with in terms of following the details of before - is the idea of applicative order versus normal order. Applicative order first evaluates the operator and operands and then applies the resulting procedure to the resulting arguments. Another way to do it - called normal order - is to not evaluate the operands until their values are needed; we keep expanding the operators until we get down to primitive procedures.
So in applicative order, we're okay with handing a non-primitive procedure like square (assuming that's not a primitive function) a value to evaluate, and we're okay with having performed operations on that value before we even hand it to square. Whereas in normal order, we won't do that - instead we'll break down square into its component parts (of two * operations) before giving it values - and we'll put off evaluating what those values will be until the last possible second.
Applicative order example:
(sum-of-squares (+ a 1) (* a 2))
(sum-of-squares (+ 5 1) (* 5 2))
(+ (square 6) (square 10))
(+ (* 6 6) (* 10 10))
(+ 36 100)
136
Normal order example:
(sum-of-squares (+ a 1) (* a 2))
(sum-of-squares (+ 5 1) (* 5 2))
(+ (square (+ 5 1))
(square (* 5 2)))
(+ (* (+ 5 1) (+ 5 1))
(* (* 5 2) (* 5 2)))
(+ (* 6 6)
(* 10 10))
(+ 36 100)
136
Note that with the normal order approach, (+ 5 1) and (* 5 2) are performed twice, whereas in the applicative order approach we perform those operations once before handing the value off to square.
1.1.6 - Conditional Expressions and Predicates
This section discusses conditional expressions using cond. SICP notes before introducing cond that there has been no way to test values as of yet (I note that they introduce cond before if - if seems like the simpler thing to discuss to me in some ways - ah, but it looks like they introduce it immediately after cond in any case). Some terminology is introduced - predicate, consequent, clauses. It's mentioned that if none of the predicates are true, then the value of a cond is undefined.
This section also introduces if. SICP notes in footnote 19 that one difference between cond and if is that the consequent portion of a cond clause can be a series of expressions that are evaluated, with the value of the final expression in a sequence being the value of thecond, whereas with if, the "⟨consequent⟩ and ⟨alternative⟩ must be single expressions." I'll note as an exception that if you use begin, you can multi-part consequents and alternatives, e.g.:
(define (test a)
(if (= a 2)
(begin (display 'potato)
(display "\n")
'yay)
'nay))

SICP goes on to describe logical operators. One thing that I initially found curious but then realized the explanation for was part of their description of and:

My initial thought was, "well, wouldn't the value in such a case be #t"? But non-false values - like the number 3, say - return as true. This is discussed in footnote 17, which says:
#fSo based on that, this is expected behavior:

Exercises
Exercise 1.1 ✅
Below is a sequence of expressions. What is the result printed by the interpreter in response to each expression? Assume that the sequence is to be evaluated in the order in which it is presented.
10
The result is 10.
(+ 5 3 4)
The result is 12.
(- 9 1)
The result is 8
(/ 6 2)
The result is 3
(+ (* 2 4) (- 4 6))
The result is 6
(define a 3)
Nothing is printed here, though an association between a name a and a value 3 is made.
(define b (+ a 1))
Nothing is printed here either, though an association between a name b and a value 4 is made.
(+ a b (* a b))
The result is 19.
(= a b)
The result is #f. 3 does not equal 4.
(if (and (> b a) (< b (* a b)))
b
a)
The result is 4 because the predicate (and (> b a) (< b (* a b))) evaluates to true.
(cond ((= a 4) 6)
((= b 4) (+ 6 7 a))
(else 25))
The result is 16 because the predicate (= b 4) is true.
(+ 2 (if (> b a) b a))
The result is 6
((* (cond ((> a b) a)
((< a b) b)
(else -1))
(+ a 1))
I misread this as excluding the last line the first time I tried to calculate (and thought it had a missing paren and should evaluate to 4). Based on correct parsing, it's 16.
Exercise 1.2 ❌
Translate the following expression into prefix form:
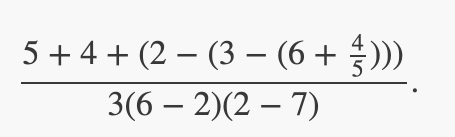
(/ (+ 5 4 (- 2 (- 3 (+ 6 4/5))))
(* 3 (- 6 2)(- 2 7)))
Answer above is correct, but initially, I actually the major / that separates the two big expressions in the middle. Doh! Infix habits are strong. Since I've been working with Scheme notation for a while, I'm gonna count this as an error - stuff should be more automated by now.
Exercise 1.3 ✅
Define a procedure that takes three numbers as arguments and returns the sum of the squares of the two larger numbers.
My First Solution
(define (square x)
(* x x))
(define (sum-of-squares x y)
(+ (square x) (square y)))
(define (sum-of-biggest-squares a b c)
(cond ((and (<= a b)(<= a c))
(sum-of-squares b c))
((and (<= b c)(<= b a))
(sum-of-squares a c))
(else (sum-of-squares a b))))
sum-of-biggest-squares is basically a biggest number checker that calls sum-of-squares.
The first cond clause checks if a is the smallest value and calls sum-of-squares with b and c if that's the case. Second cond clause does similar but checks if b is the smallest value and calls sum-of-squares with a and c if that's the case. If neither a nor b are the smallest value, then that only leaves c as the smallest value, which is addressed in the else clause.
A Question, & A Bad Solution
One issue worth thinking about - do we want to see if the value being tested is less than the other value, or less than or equal to the other value?
E.g. do we want:
(and (< a b)(< a c))
or
(and (<= a b)(<= a c))
Suppose we take the first approach and we have the arguments 4 4 5 as our a b and c, respectively. So we've got this variant procedure:
(define (sum-of-biggest-squares2 a b c)
(cond ((and (< a b)(< a c))
(sum-of-squares b c))
((and (< b c)(< b a))
(sum-of-squares a c))
(else (sum-of-squares a b))))
The first cond line fails cuz 4 isn't less than 4 ((< a b)). The second cond line fails cuz, again, 4 isn't less than 4 ((< b a)). So then we decide that c, or 5, is the smallest number .... which is wrong.

If we don't test whether a is less than or equal to b and c, then we're not able to say as much from each test. By the time we get to the else clause, we want to be able to confidently say "c is less than, or at best tied with, a or b." But to be able to say that, we need to look at whether a was equal to b or c in the first cond clause (and not just whether it was less than), and likewise with whether b is equal to c or a.
OTOH with the way I initially wrote it, everything works fine:

Looking at Other Solutions, Part 1
I found an answer structured in a very similar manner to mine. However, aelanteno correctly points out that once you've run the first cond line, you know something about a, and so you can make the second line more succinct, which is a great point:
define (sum-of-squares-of-two-larger-numbers a b c)
(cond ((and (<= a b) (<= a c)) (sum-of-squares b c))
((<= b c) (sum-of-squares a c))
(else (sum-of-squares a b))))
I'd like to note something at this juncture about what aelanteno says:
If that first line isn't true, then we know thatais one of the two larger numbers so we can just check ifb<=c.
This isn't really a criticism of aelanteno, since the exercise itself talks about "the two larger numbers." But there might not actually be two larger numbers - for example, if there is a 2-way tie (as is the case when providing our function with the arguments 4 4 5). There might not be any larger numbers - for example, if there is a 3 way tie. But what we can say after running (and (<= a b) (<= a c)) is that a is one of the acceptable choices for one of the values to pass to sum-of-squares, because if there is a tie - say between a and b - then it doesn't actually matter which one you choose. I note that I've caught myself talking in a way that ignores the tie issue and may in fact do so elsewhere in this post 🙂
My Second Solution
After reading aelanteno's first solution I came up with this different way of solving the problem. It uses a helper procedure that returns the appropriate values in a list form, and uses apply so that the elements of the list returned from the helper procedure are passed as individual arguments to sum-of-squares:
(define (sum-of-biggest-squares-apply a b c)
(apply sum-of-squares (biggest2of3 a b c)))
(define (biggest2of3 a b c)
(cond ((and (<= a b)(<= a c))
(list b c))
((<= b c)
(list a c))
(else (list a b))))
I'm not sure if this is an improvement over my previous solution. I guess it's okay if you want to only read the body of sum-of-biggest-squares-apply and otherwise treat biggest2of3 as a black box. It's nice to try different ways of solving things, though.
Looking at Other Solutions, Part 2
After coming up with a my second solution, I went back to aelanteno's page and read her second solution.
(define (sum-of-squares-of-two-largest-numbers x y z)
(sum-of-squares
(largest-of-three-numbers x y z)
(second-largest-of-three-numbers x y z)))
(define (largest-of-three-numbers x y z)
(max (max x y) (max y z)))
(define (second-largest-of-three-numbers x y z)
(if (< x z)
(min (max x y) z)
(max (min x y) z)))
(define (min x y) (if (< x y) x y))
(define (max x y) (if (> x y) x y))
Ah this is interesting.
min and max seem self-explanatory.
I think second-largest-of-three-numbers is the most interesting part of the program, so I will focus my comments on that. second-largest-of-three-numbers checks if x is less than z. If it is, that means that z is going to be one of the top two values, given that there are only three values and given that we definitely know one value is less than another. The procedure then tries to get the higher of x and y with (max x y). After (max x y) returns a single value, the procedure then tries to get the lesser of the remaining two values with min. It tries to get the lesser of the remaining two values since it's trying to get the second largest number.
On the other hand, if x isn't less than z, that means x is equal to or greater than z. So we know in this scenario that x is at least equal to z, and we now want to determine its relation to y. Imagine if x y z was 5 3 4. 5 isn't less than 4, so we go to (max (min x y) z))). The inner expression is (min x y) because it wants to return the lesser of x and y for comparison to z. In our example with arguments 5 3 4, we wind up comparing the 3 and the 4 and getting the maximum value of those two values, and this makes because we're trying to find the second largest value. So basically, we wind up excluding the 5 from the "last round" of consideration.
I think the manner in which largest-of-three-numbers works is straightforward and so I won't go into detail on that.
One thing I made a big deal about earlier in discussing my cond-based solution was handling ties between values. This code handles ties fine, but I did not find it immediately obvious why. It's because of the fact that it's building on min and max. min and max both implicitly cover the case of ties. Consider min. It says that if x is less than y, then return x; otherwise, return y. What's "otherwise"? Otherwise includes the case where x and y are tied. So min has an opinion about what value to return in case of a tie - ties aren't a case that was left out.
So what in second-largest-of-three-numbers if you have a situation where x y and z are 4, 4, and 5 respectively? x is less than z. We get the max of x and y (so, y, since x is not greater than y, but both values are 4, so it doesn't matter), and then the min of y and z (or 4 and 5), which is 4, which is the correct value.
Unanswered Questions 🤔
Advantages to Prefix Notation
In section 1.1.1, SICP describes some advantages to prefix notation, such as how an operator can take an arbitrary number of arguments.
SICP also mentions nested expressions as an advantage of prefix notation. But you can have nesting in infix, no?
((3 + 4) + (5 * 6))
So I'm not sure I understood that point.